用 Python 学强化学习: Q-Learning 迷宫示例
[caption id="attachment_70386" align="alignnone" width="2017"] Q Learning强化学习算法(机器学习/人工智能)[/caption]
强化学习(Reinforcement Learning, RL)是一种让智能体/Agent通过与环境交互、试错学习来获得最优行为策略的机器学习方法。本文用一个简单的 Q-learning 迷宫示例,帮助你快速理解强化学习的基本原理。
Q Learning强化学习算法(机器学习/人工智能)[/caption]
强化学习(Reinforcement Learning, RL)是一种让智能体/Agent通过与环境交互、试错学习来获得最优行为策略的机器学习方法。本文用一个简单的 Q-learning 迷宫示例,帮助你快速理解强化学习的基本原理。
强化学习入门:从试错中学习的艺术 Reinforcement Learning 101: The Art of Learning by Trial and Error 深度解析强化学习:Q-Learning算法详解 Deep Dive into Reinforcement Learning: Understanding the Q-Learning Algorithm 机器如何学会自己做决定?强化学习告诉你答案 How Do Machines Learn to Make Their Own Decisions? Reinforcement Learning Explained 从奖励中学习:人工智能的“试错智慧” Learning from Rewards: The Trial-and-Error Intelligence Behind AI
一、什么是强化学习?
强化学习的世界中包含五个关键要素:- Agent(智能体):做决策、执行动作的主体
- Environment(环境):智能体所处的世界
- State(状态):当前环境的描述
- Action(动作):智能体可采取的操作
- Reward(奖励):环境反馈,用来衡量动作的好坏
二、Q-Learning 原理
Q-learning 是最经典的强化学习算法之一。它通过学习一个 Q 表(Q-table)来记录每个“状态-动作”对的价值。 更新公式如下:
[math] Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s', a') - Q(s,a)] [/math]
其中:
- [math] \alpha [/math]:学习率(Learning Rate)
- [math] \gamma [/math]:折扣因子(Discount Factor)
- [math] r [/math]:奖励(Reward)
- [math] s' [/math]:下一状态(Next State)
三、迷宫环境设计
定义一个 3×5 的迷宫:- 0:空地
- -1:墙
- 1:出口(目标)
四、完整 Python 实现代码
import numpy as np
import random
# 1️⃣ 定义迷宫
maze = np.array([
[0, 0, 0, -1, 1],
[0, -1, 0, -1, 0],
[0, 0, 0, 0, 0]
])
n_rows, n_cols = maze.shape
actions = ['up', 'down', 'left', 'right']
Q = np.zeros((n_rows, n_cols, len(actions)))
# 2️⃣ 超参数
alpha = 0.1
gamma = 0.9
epsilon = 0.1
episodes = 500
# 3️⃣ 辅助函数
def is_valid(state):
r, c = state
return 0 <= r < n_rows and 0 <= c < n_cols and maze[r, c] != -1
def next_state(state, action):
r, c = state
if action == 'up': r -= 1
elif action == 'down': r += 1
elif action == 'left': c -= 1
elif action == 'right': c += 1
return (r, c)
def get_reward(state):
r, c = state
if maze[r, c] == 1: return 10
elif maze[r, c] == -1: return -1
return -0.1
# 4️⃣ 训练循环
for episode in range(episodes):
state = (2, 0)
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action_idx = random.randint(0, len(actions)-1)
else:
action_idx = np.argmax(Q[state[0], state[1]])
action = actions[action_idx]
next_s = next_state(state, action)
if not is_valid(next_s):
reward = -1
next_s = state
else:
reward = get_reward(next_s)
Q[state[0], state[1], action_idx] += alpha * (
reward + gamma * np.max(Q[next_s[0], next_s[1]]) - Q[state[0], state[1], action_idx]
)
state = next_s
if maze[state[0], state[1]] == 1:
done = True
print("✅ 训练完成!")
# 5️⃣ 查看学到的路径
state = (2, 0)
path = [state]
while maze[state[0], state[1]] != 1:
action_idx = np.argmax(Q[state[0], state[1]])
next_s = next_state(state, actions[action_idx])
if not is_valid(next_s) or next_s in path:
break
state = next_s
path.append(state)
print("🗺️ 学到的路径:", path)
五、运行结果
运行上面的代码后,你会看到类似输出:
✅ 训练完成!
🗺️ 学到的路径: [(2, 0), (2, 1), (2, 2), (1, 2), (0, 2), (0, 3), (0, 4)]
这说明智能体成功学会了走出迷宫 🎯
六、总结
强化学习使机器能够通过反馈学习最优策略,这类似于人类通过经验学习的方式。 Q-Learning 是许多现代强化学习算法的基础,包括深度 Q 网络(Deep Q-Networks, DQN)。 这个简单的示例展示了完整的强化学习循环:探索 → 反馈 → 改进。- Q 表:保存每个状态-动作的价值
- ε-greedy 策略:平衡探索与利用
- 奖励函数设计:引导智能体形成目标导向行为
- 强化学习思想:通过试错和奖励反馈不断改进策略
相关文章:
- 智能手机 HTC One M9 使用测评 虽然我对手机要求不高, 远远没有像追求VPS服务器一样, 但是怎么算来两年内换了四个手机, 先是三星 S4 用了一年多, 然后 Nokia Lumia 635 Windows Phone, 后来又是 BLU, 半年多前换了...
- 按揭贷款(房贷,车贷) 每月还贷计算器 去年给银行借了17万英镑 买了20万7500英镑的房子, 25年还清. 前2年是定率 Fix Rate 的合同 (年利率2.49%). 每个月大概是还 700多英镑. 有很多种还贷的计算方式, 定率/每月固定 是比较常用的. 简单来说就是 每个月交的钱是...
- 第一次私校家长会: 原来家长比孩子还卷 前几天参加了娃的第一次家长会,和几位家长聊下来,真是个个都很厉害。不光孩子们卷,家长也一样卷,一眼望去基本都是 Dr/博士。娃还调侃我一句:“这有什么的,你不也是 Dr 吗?” 我心里默默想:还好没写学校名字,不然我这野鸡大学的头衔真拿不出手 😂。 私校里真是人才济济,乐器过 8 级的太常见了,卷得不得了。我还问过娃,是想当 big fish in a small pond...
- 给孩子第一台NUC小电脑 Next Unit of Computing Next Unit of Computing (NUC) is a line of small-form-factor computers...
- 和媳妇约个会: 剑桥的过桥米线 Dumpling Trees Dumpling Trees 是位于剑桥 Cherry Hilton 附近的一家中式餐厅,以云南特色的过桥米线闻名。店内环境宽敞整洁,菜品丰富,除了经典的米线,还有各类小吃、烧烤和炒饭,味道地道,分量十足。过桥米线的汤底鲜香,配料新鲜,包括鸡肉、鱿鱼、虾等食材,顾客可以自己下锅涮熟,既好吃又有趣。餐厅提供免费停车,但需在店内登记车牌,适合家庭聚餐或周末小聚。 剑桥 Cherry Hilton 那边有一家叫 Dumpling Trees 的过桥米线店,两三年前的冬天我们去吃过一次(剑桥 Dumpling Tree...
- 微信PC端程序占用了1.39 TB的空间! 快速清理微信占用空间 前两天我的 C 盘剩余空间突然变红了,我随手一查,竟然发现微信 PC 端程序居然占用了 1.39 TB 的空间,简直不可思议。在手机上,微信同样是名列前茅的“吞空间大户”,在 设置 → 通用 → 手机存储空间 里几乎稳居第一。 更离谱的是,这些空间大多并不是因为聊天记录,而是各种缓存文件、视频、图片和被动接收的文件所堆积起来的。平时我们只是点开看一眼,就算没保存下来,微信也会悄悄把它们留在本地,占据大量磁盘。尤其是群聊里转发的视频和文件,日积月累就成了一个“隐形黑洞”。...
- C++的左值/lvalue, 右值/rvalue和右值引用/rvalue references C++ 左值(lvalue)、右值(rvalue)与右值引用(rvalue reference) 理解 C++ 中的左值、右值及其引用形式,是掌握现代 C++(尤其是 C++11 以后的移动语义/move和完美转发/perfect forwarding)必不可少的基础。 📌 什么是左值(lvalue) 左值指的是有名字、可寻址的对象,通常可以出现在赋值语句的左侧。 int x...
- 比特币最近波动有点大: 一天牛市一天熊 比特币10万美金以内都是最后上车的机会! 比特币近期的价格波动可以归因于多个关键因素,包括地缘政治动态、监管变化以及加密行业内的重大安全事件。其中一个主要影响因素是美国前总统唐纳德·特朗普对乌克兰和加密货币监管的立场变化。据报道,特朗普再次当选,他可能会推动减少美国对乌克兰的支持,这可能会影响全球金融市场和风险偏好。同时,特朗普正在将自己塑造为亲加密货币的候选人,表示有意让美国成为一个更加友好的加密货币环境。这一立场引发了市场对监管政策可能发生变化的猜测,导致市场情绪在乐观和不确定性之间波动。 特朗普对俄乌战争的态度 美国第43届总统唐纳德·特朗普已经在2025年1月当选并正式上任(第二次),那么他的政策可能会对比特币价格的波动产生更加直接和显著的影响。他政府对乌克兰和加密货币监管的立场已经不再是猜测,而是正在实际塑造市场的关键力量。 特朗普(Donald Trump)减少美国对乌克兰的支持,全球投资者可能会预期地缘政治稳定性发生变化,从而增加对比特币作为避险资产的需求。同时,他的亲加密货币立场可能正在推动市场的乐观情绪。如果他的政府推出有利于加密行业的监管政策,例如明确的合规指南或减少监管审查,可能会吸引更多机构投资者进入市场,并促进更广泛的加密货币采用。然而,政策的快速变化也可能导致短期市场剧烈波动,因为市场需要时间来消化新的政策动向。 朝鲜黑客盗取Bybit交易所15亿美元的ETH 另一个显著影响比特币价格的事件是近期涉及朝鲜黑客组织“Lazarus”的15亿美元以太坊被盗案件。据报道,Bybit交易所(全球第二)这些被盗的ETH已经被清洗,此次大规模黑客攻击引发了人们对加密行业安全性的担忧。此类安全事件不仅会削弱投资者信心,还可能引发更严格的监管审查,导致短期市场动荡。此外,被盗资金的大规模流动和出售可能对市场流动性造成冲击,进一步加大价格波动。随着这些事件的持续发酵,比特币价格正受到政治决策、监管预期以及安全挑战等多重因素的影响。 与此同时,与朝鲜黑客组织 Lazarus 相关的 15 亿美元以太坊被盗事件仍在影响加密市场。由于这些被盗 ETH 已被清洗,人们对加密行业安全漏洞的担忧持续存在,同时也可能引发更严格的监管审查。政治、监管和安全等多重因素交织在一起,共同导致了比特币近期的剧烈价格波动。...
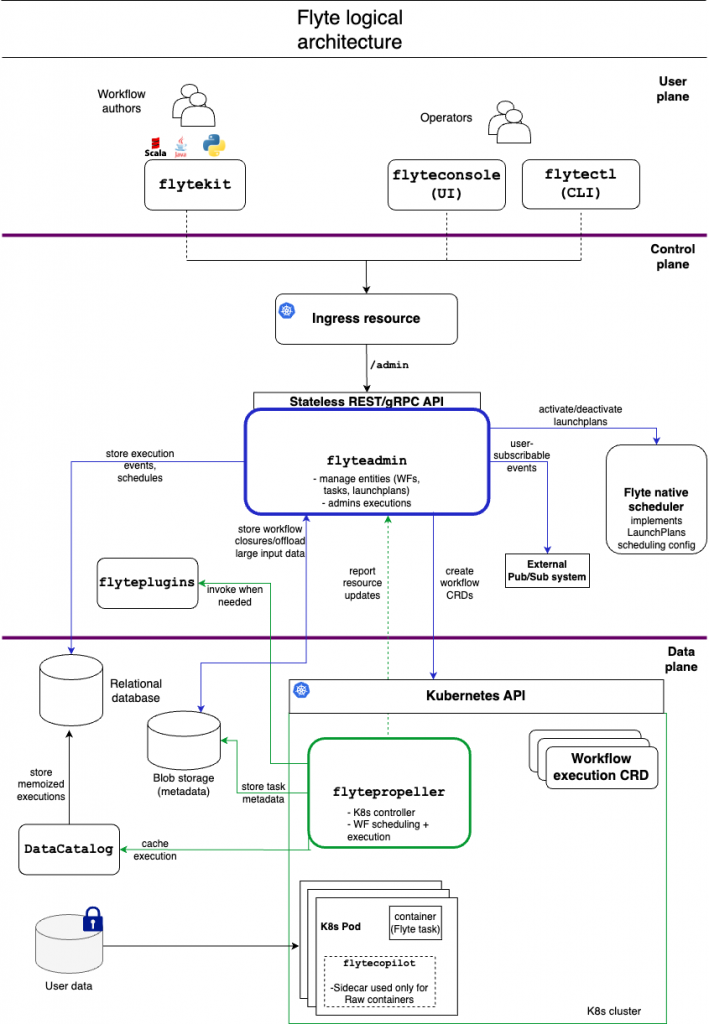
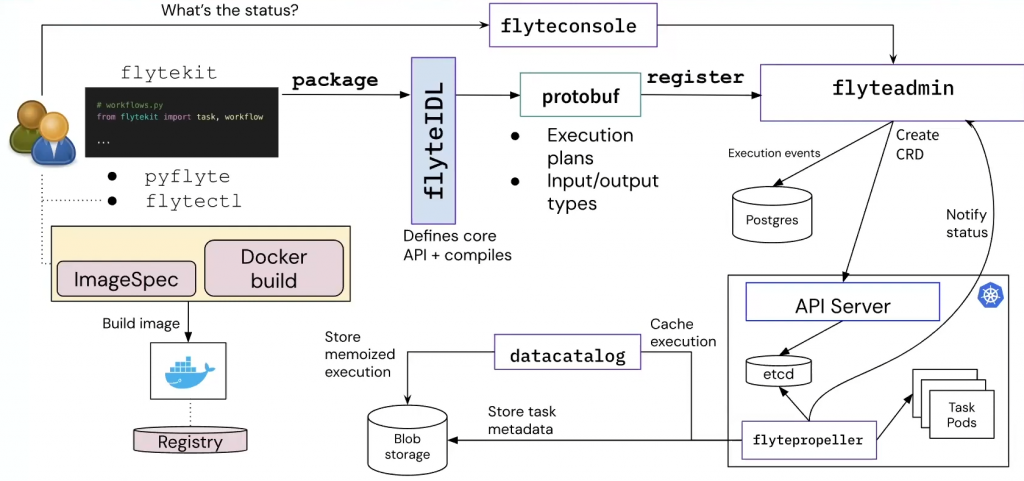
 入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。
入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。