聊聊拼多多的商业模式
 作为业余爱好,一直很喜欢研究企业的商业模式。我以往觉得电子商务这个赛道竞争很激烈,生意很难做,尤其是中国当前的环境下,近些年在商业模式上也没有太多有意思的创新。快两年前,写过一点关于拼多多的,但主要是批评,我不喜欢它的生意模式,我觉得它的壮大会打压中国的品牌成长。这个观点至今依然成立,不过,除此以外,那个时候我对于拼多多的理解还是比较浅薄的。随着这两年拼多多的成功,我觉得我看到了它越来越多以前没有看到的东西。这些东西让我越来越觉得,黄峥,真的是个眼光很长远,执行上也很厉害的人。
作为业余爱好,一直很喜欢研究企业的商业模式。我以往觉得电子商务这个赛道竞争很激烈,生意很难做,尤其是中国当前的环境下,近些年在商业模式上也没有太多有意思的创新。快两年前,写过一点关于拼多多的,但主要是批评,我不喜欢它的生意模式,我觉得它的壮大会打压中国的品牌成长。这个观点至今依然成立,不过,除此以外,那个时候我对于拼多多的理解还是比较浅薄的。随着这两年拼多多的成功,我觉得我看到了它越来越多以前没有看到的东西。这些东西让我越来越觉得,黄峥,真的是个眼光很长远,执行上也很厉害的人。
最早的时候,我以为拼多多的核心就是低质量、低价的策略。后来我渐渐明白,所谓的低价策略,只是最肤浅的一个表象。
如果退到十年以前,应该很少有人能同意,在如此激烈的电子商务赛道上,已经有了老牌的阿里巴巴,还有重供应链的京东,拼多多能够挤进来,分到一杯羹。而如今,不仅如此,它的增长居然已经让这两家都难以望其项背。
说到阿里巴巴,如今看,它还是犯了一个企业扩张以后变得局限、傲慢的通病。早些时候马云就评论京东说这种重资产玩不转,到后来张勇则认为拼多多只会帮助阿里巴巴教育用户和开拓市场,阿里巴巴错过了太多的机会。
拼多多的核心商业模式是什么,招股书中讲是中国的 Costco+Disney,零售+娱乐。但是它没有对比阿里巴巴和京东,来进一步细致地说明它是打算怎么赚钱的。看起来这些零售电商很接近,其实很不一样。阿里最值钱的是什么,是商家;但是拼多多呢,是消费者。就连对于 “砍一刀” 这样的基于社交的病毒式营销,也是基于消费者这个核心。拼多多教育用户,你要关心你买的产品和价格,但不要关心是什么品牌、是谁生产的。拼多多不在乎丢失商家,而是推行白牌商品,达到极致的性价比,以最简单的低价方式来留住用户。所以说,传统电商那套基于流量变现的策略在拼多多这里行不通了,拼多多更关心的是单一性价比高的商品,谁来拿订单?很简单,价低者得。
Costco 玩法的其中一个核心就是由它来代替用户选择性价比高的品牌,利用巨大的订单量,来和生产的商家谈价格。在同样具备规模效应的情况下,这是它和沃尔玛这种靠商品品类之全而获得用户的商业模式来说,最大的优势之一。比方说,在 Costco 买衣服,你不会找到很多的品类,每种衣服的类型可能就那么一两种衣服,但是衣服的质量可以,而且性价比没的说。一句话概括,单一的种类,巨大的订单量。
阿里也好,京东也好,它们都可以把消费者直接对接到商家,砍掉中间环节,但是这样的消费者依然是没有议价能力的,因为消费多少不能提前确定,每一单的规模又小得可怜。但是类似于 Costco,拼多多的做法是什么?把大量消费者的需求捆绑起来,它们出动去和生产产品的商家谈,这就让商家愿意去用一个更低价格来换取很早就可以确定的大订单。商家被迫报低价来抢单,商家和商家之间抢拼多多这个大客户,这种模式和白牌商品有着最天然的契合。可以认为,这是团购的升级版,我觉得这才是拼多多最核心的玩法。
提到了 Costco,再来说 Disney,这主要说的是娱乐和社交。和传统电商个人选择和购买的模式不同,拼多多可以利用团购的本质来强化社交这个行为。因为团购需要多人参与,拼多多就可以提供一个可以游戏的平台,这也是其它传统电商很难和它竞争的一个方面。无论是养成类的多多果园(这个真是一个提高日活的绝招)还是社交裂变类的砍一刀,还有那些对于很多人来说看起来并不高级的幸运转盘……购物变成了只是游戏过程中的一个环节。
再来看看拼多多扩张的过程当中,那些成功而重要的决策。
首先是 “砍一刀” 这样的病毒式营销,这可能是像我这样的人最早听说拼多多的时间。那段时间,恰好是微信摇一摇春晚大肆撒钱的事情发生之后。众所周知,腾讯的这一方面的眼光总是很独到,藉由微信等等流量平台,他们也有非常大的用户数据和这方面的经验。腾讯投资了拼多多,或许这盘大棋中,也告知了拼多多这样一个事实——大量的网民们,他们的微信账户有着红包摇来的钱,这是最好的建立拼多多性价比消费心智的时间。配合 “砍一刀”,拼多多的初始的大规模获客就这样做到了。
第二件火爆的事情可以说是拼多多玩的 “仅退款”,阿里和京东根本当时根本就没法快速跟进。因为他们需要考虑这些极度便利消费者的措施,对于品牌相当负面的摧残和打压。品牌就意味着溢价,有了溢价就没法极度地考虑性价比。从这个角度来说,长期看,拼多多的市场很大,并且阿里和京东根本没有办法去抢,无论是国内还是海外。阿里也许能把很多第二产业、第三产业做成,能把阿里云做成,甚至能把芯片也搞起来,但是传统电商,对于大多数人来说,考虑到目前大多数人的消费习惯和能力,我觉得它长期下来是不可能搞得过拼多多的。
再有,拼多多对于资金的分配,也是极致的典范。想想阿里什么都要投钱,铺开来如此之大的摊子,什么都搞,拼多多非常本分,就做自己风格的电子商务,就是扎根于农村下沉市场,和阿里、京东比起来极少的员工数,尽可能地避免重资产,连办公楼都是租的。每次财报,都是不分红,并且低调地强调未来的风险,最近火爆的 AI,拼多多也似乎尽量去避免接触,这样的管理层,在如今这个习惯于画大饼的世界似乎真是独一无二。
最后,我想到了微博和小红书。微博是大 V、名流为核心的玩法,无名人士的发声微不足道;小红书呢,则是基于草根的玩法,它的推荐系统是最核心的资产,它可以让一个无名之辈的帖子出现在感兴趣的用户的眼前。我觉得这是小红书和微博最大的区别,这也是微博已经是上一代互联网产品,逐渐衰落的原因之一。以此类比,阿里巴巴上的品牌企业,就是大 V 和名流;拼多多上的无数白牌商家,就像是不知名的草根。单一草根势单力薄,但是拼多多这样的平台把他们的力量汇聚起来,消费者买到东西的时候兴许不知道是哪家草根商家生产了他的货品,但是千千万万的草根商家就能够借助这个平台,靠着生产白牌产品,把自己的小小生意做下去。这样看,其中的历史意义显而易见。
这林林总总的事情,无论是战略还是实施,都让我觉得拼多多真是一家非常厉害的企业,黄峥真的是一个很厉害的人。黄峥受到段永平影响很大,他要 “做对的事情,并把事情做对”,但我不知道对于他来说,什么样的事情是对的事情。当然,我觉得我还是没有很深刻地读懂拼多多,以上只是我现在的思考,这真是一家太有意思的企业。
《四火的唠叨》文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接
你可能也喜欢看:
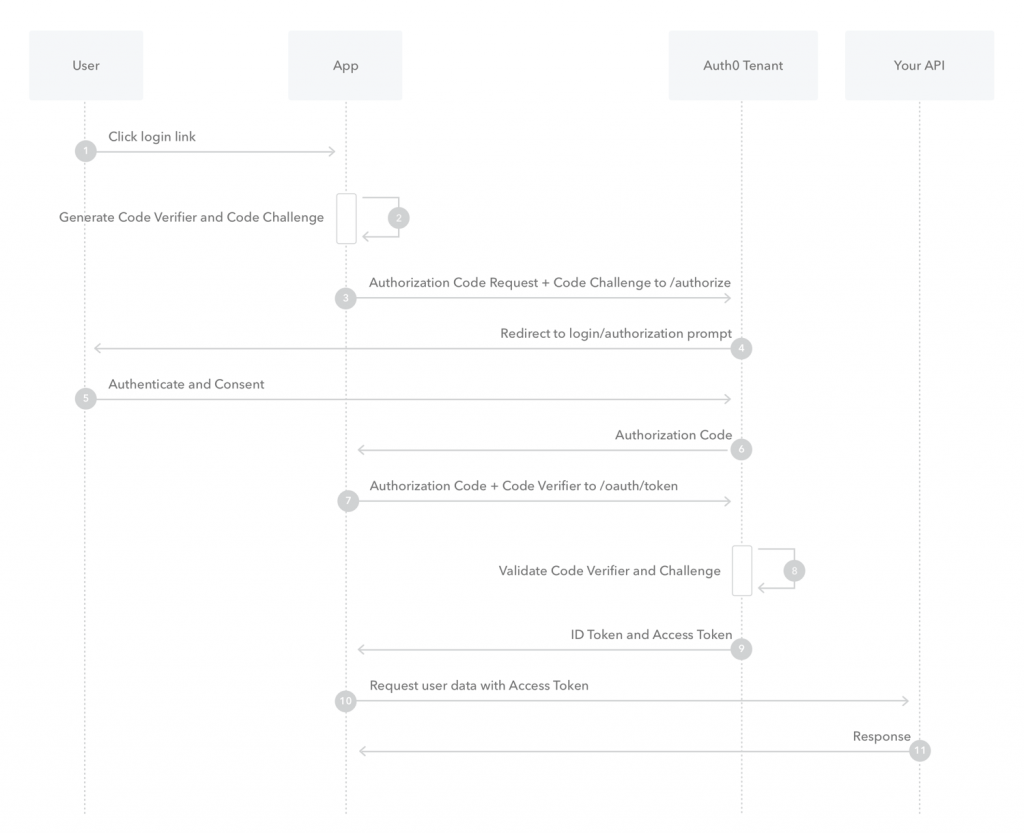
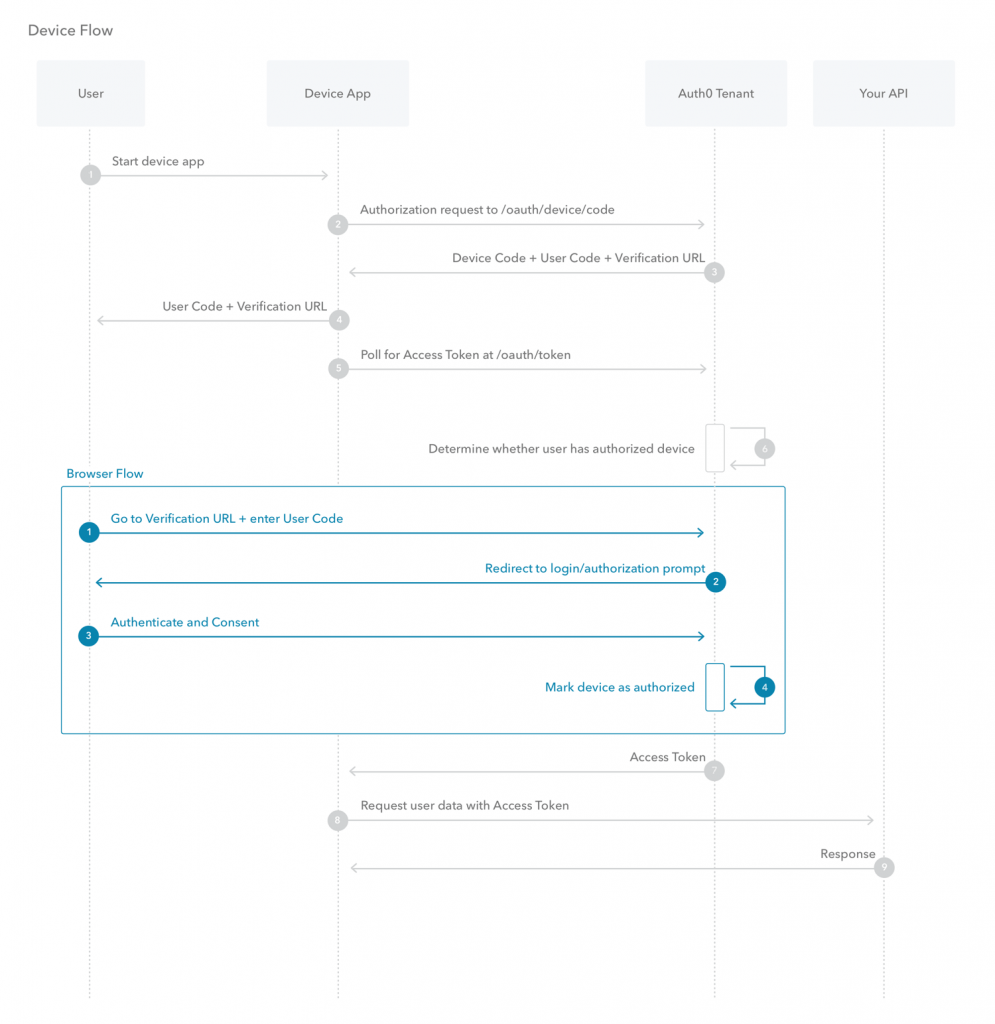
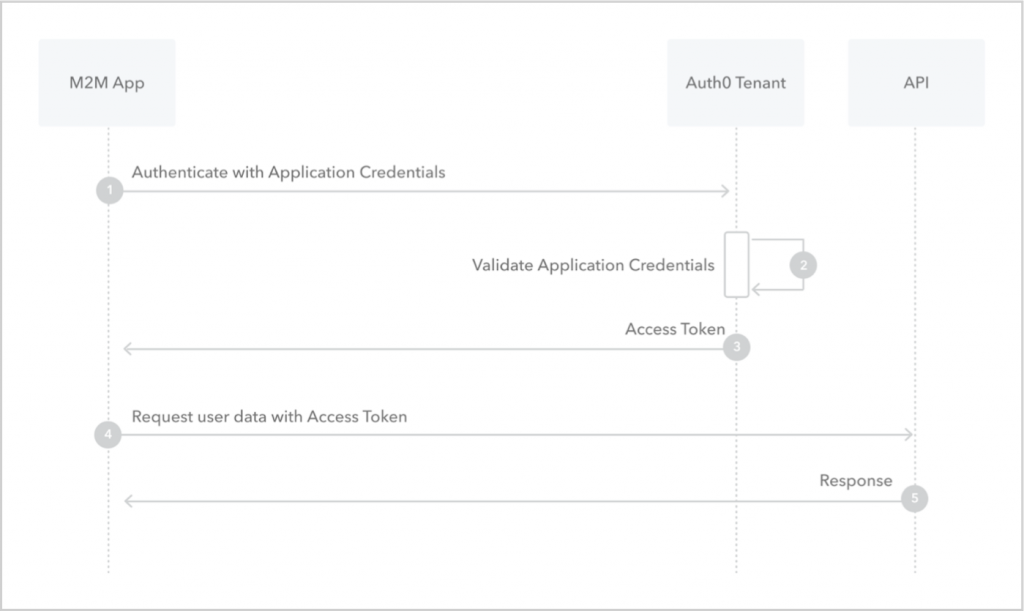
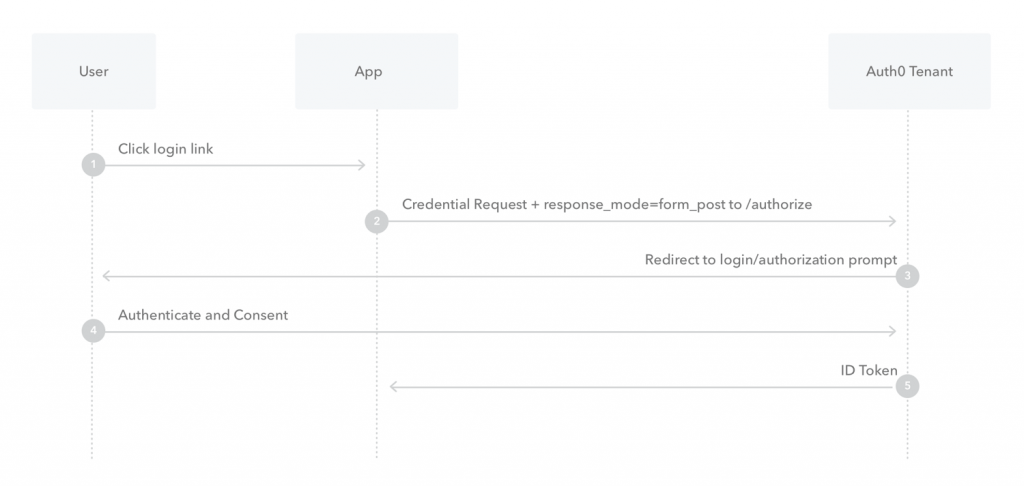
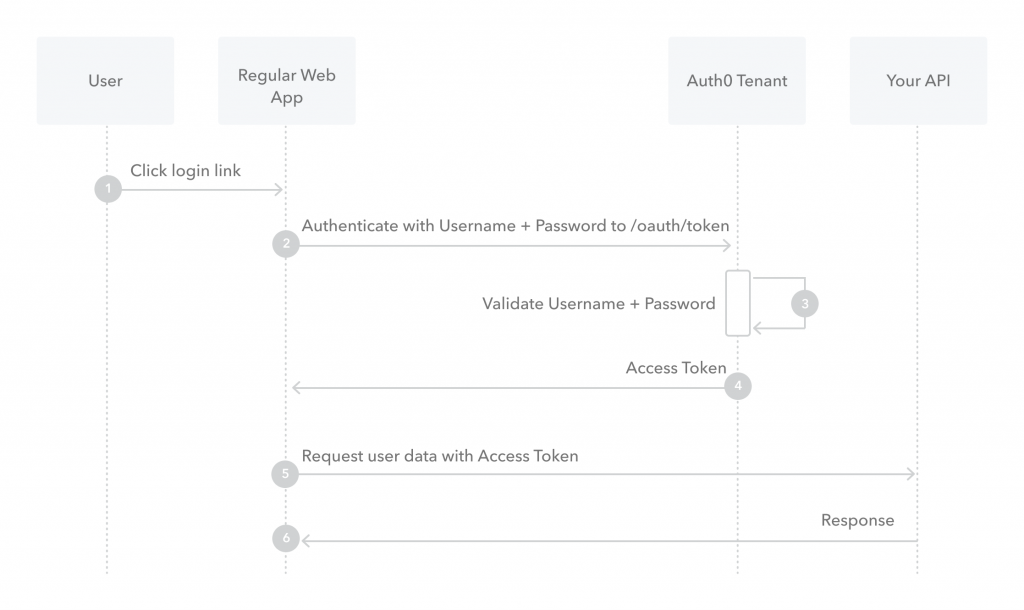
 首先,从高维度看,OAuth 是要解决什么问题?
首先,从高维度看,OAuth 是要解决什么问题?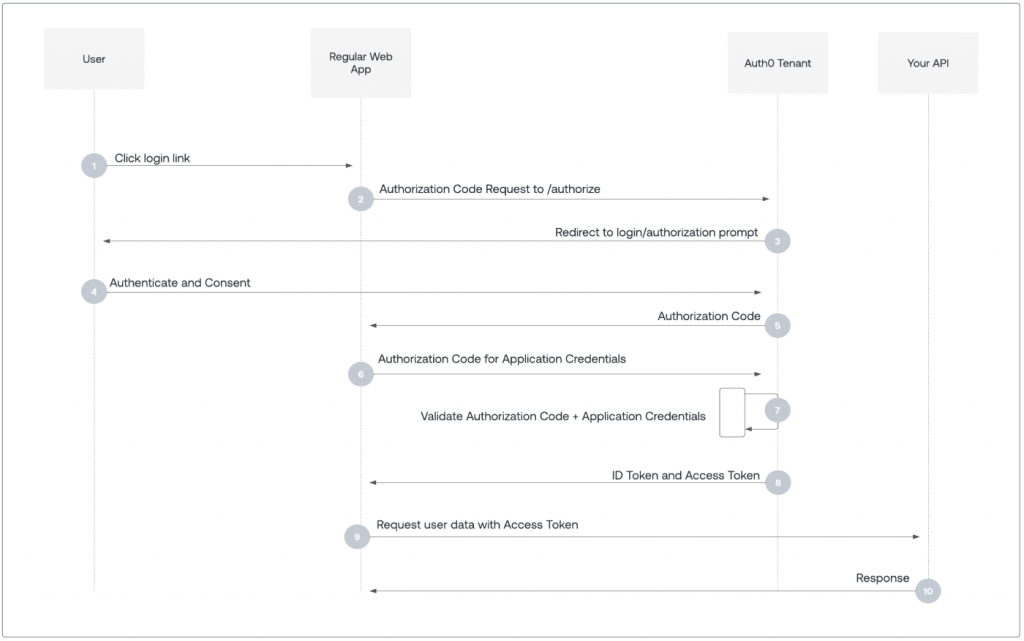
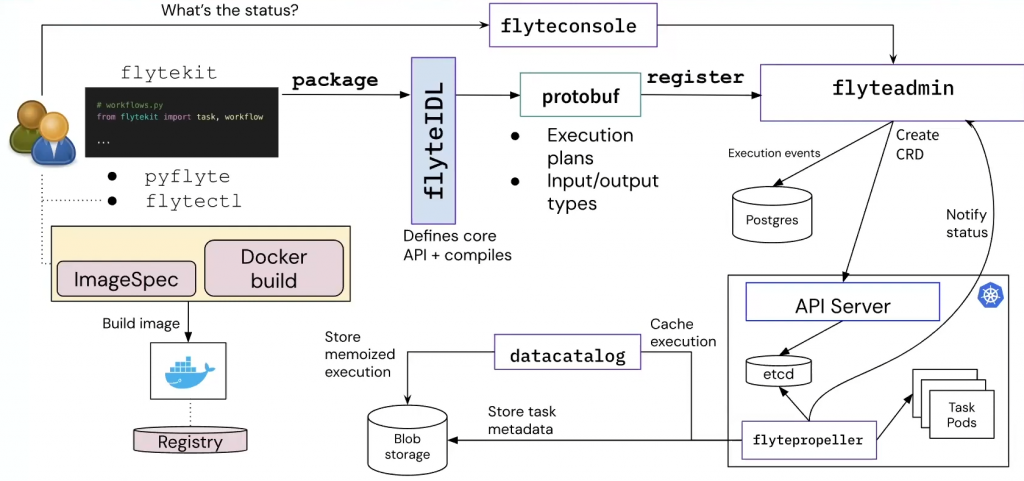
 入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。
入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。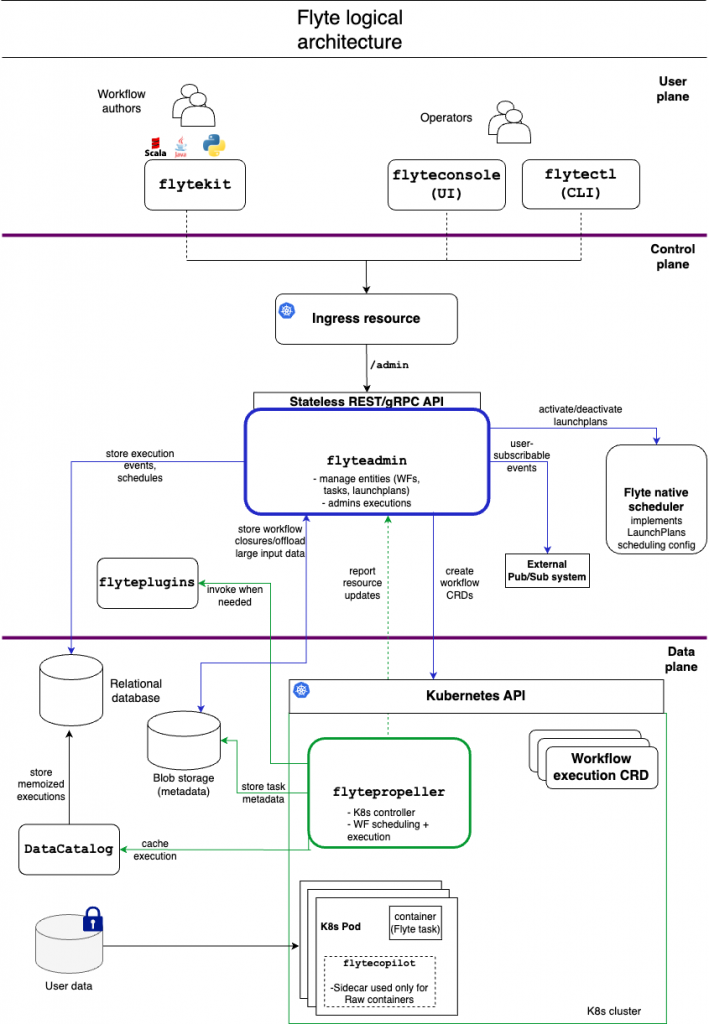
 自去年秋天
自去年秋天 今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。
今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。 分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如
分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如 



 就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
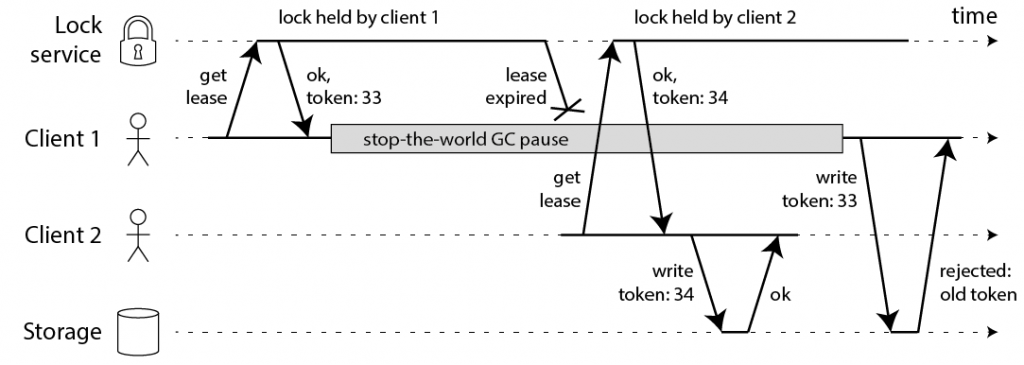
就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。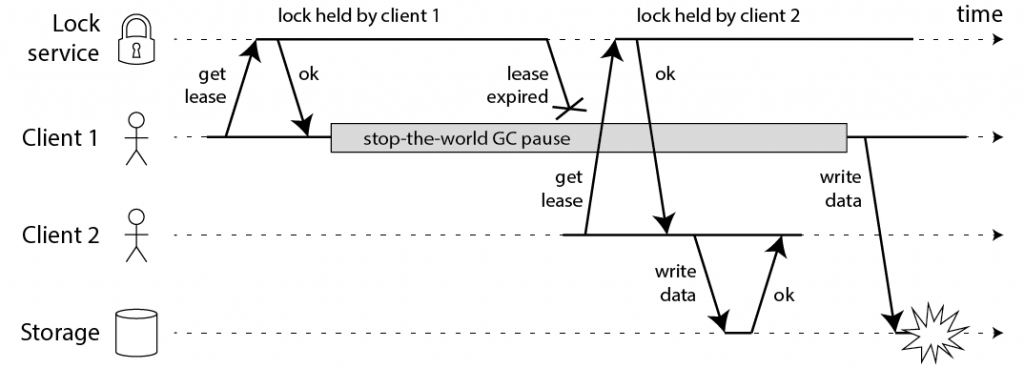
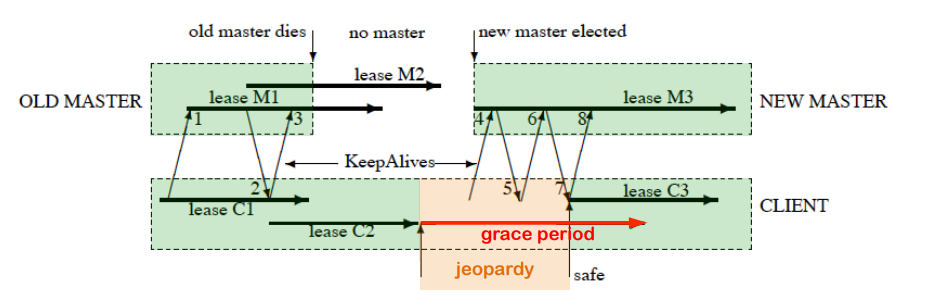
 郭德纲说过,如果你每天做的事情是你喜欢做的,那就是老天爷赏饭吃。这样的情况只在少数人身上发生,而我大致就是这样的少数人——不能说每天如此,但是在我职业生涯八成以上的时间,我工作做的事情,恰恰就是我喜欢做的。不过,今年我从一个做平台的 Gateway 组换到了一个做产品的 Order 组,我察觉到情况有了变化,这里面原因有些复杂,但明确的是,impact 是有,但做这个产品工程师并不是我所喜欢的。回头想起来,过往一直都是一个 platform engineer,这算是我第一次做 product engineer,也许这个角色并不适合我。
郭德纲说过,如果你每天做的事情是你喜欢做的,那就是老天爷赏饭吃。这样的情况只在少数人身上发生,而我大致就是这样的少数人——不能说每天如此,但是在我职业生涯八成以上的时间,我工作做的事情,恰恰就是我喜欢做的。不过,今年我从一个做平台的 Gateway 组换到了一个做产品的 Order 组,我察觉到情况有了变化,这里面原因有些复杂,但明确的是,impact 是有,但做这个产品工程师并不是我所喜欢的。回头想起来,过往一直都是一个 platform engineer,这算是我第一次做 product engineer,也许这个角色并不适合我。 最近有些思考,想在这里随便聊一下拼多多和品牌的话题,记录一下。
最近有些思考,想在这里随便聊一下拼多多和品牌的话题,记录一下。